¿Qué es SqlAlchemy? Prueba la v2.0 para acceder a bases de datos desde Python
¿Has escuchado sobre SQLAlchemy y su nueva versión 2.0, pero no sabes bien qué es? SQLAlchemy es una de las librerías más usadas de Python a la hora de tratar con bases de datos.

¿Qué es SQLAlchemy?
SQLAlchemy es un SQL toolkit de código abierto para interaccionar con bases de datos desde Python. SQLAlchemy proporciona una interfaz de alto nivel para realizar operaciones comunes a bases de datos de diferente naturaleza, de una manera sencilla, abstracta y generalizada, sin tener que atender demasiado a las especifidades de cada una de ellas.
A este tipo de librerías se las conoce como ORM (en inglés Object-Relational Mapping). Conozcamos un poco más sobre este concepto.
¿Qué es un ORM?
La finalidad de un ORM es mapear (relacionar) entidades de una base de datos y objetos (p.e clases de Python) de un determinado lenguaje de programación con tablas de una base de datos. Son muy comunes en los paradigmas de programación orientada a objetos, ya que hace uso de ellos para ofrecer una abstracción y una manera de interactuar con las bases de datos en un manera Pytonica sin necesidad de utilizar directamente queries de SQL para ello. Se encargará de realizar las operaciones en el motor de sql de manera transparente para el usuario.
Ventajas de usar un ORM en Python
Tener nuestras entidades como objetos en Python puede ser muy interesante a la hora de gestionar aplicaciones e interactuar(consulatar, hacer updates…) de manera sencilla con ellos.
Uno de las ventajas más destacables es que nos podemos abstraer y ser agnósticos a la base de datos con la que trabajemos. SQLALchemy tiene disponible una serie de dialectos, que se pueden extender y se han extendido (ElasticSearch…)
Otras cosas de las que SQLAlchemy se ocupa por nosotros es la posibilidad de gestionar un pool de conexiones, proveer un context manager, prevención de inyección SQL…
Contras de usar un ORM en Python
Las cosas se pueden complicar con operaciones complejas. Mientras que nos ofrece una optimización de queries, cuando empezamos a hacer joins, agrupaciones y queries nesteadas a lo mejor nos queda una sintaxis bastante confusa, a lo peor sufriremos llevándolas a cabo. Muchos ORMs deja ejecutar SQL en crudo, pero perdiendo gran parte de su propósito.
Como siempre, al añadir un nivel extra de abstracción, la complejidad general podrá amentar, al mismo tiempo que debuggear se puede hacer más complejo al abstraernos de los detalles de la capa de bases de datos.
Ahora que ya sabemos más sobre qué es SQLAlchemy y qué nos permite hacer, veamos con más detalle sus elementos claves.
Elementos clave de SQLAlchemy
En cualquier momento puedes bucear en la documentación de SQLAlchemy. Sin embargo, me gustaría comentar brevemente los conceptos clave con los que podrás empezar a trabajar con esta herramienta, teniendo una idea de lo que tenemos entre manos.
Por ejemplo, ¿cuál es la diferencia entre Engine y Session dentro de SQLALchemy?
Engine: Es parte del core de SQLAlchemy, gestionando y proveyendo las conexiones a la base de datos como API de bajo nivel. Es capaz de manejar una pool de conexiones, transacciones y ejecución de comandos SQL. Normalmente, se crea al inicio de la aplicación y se utiliza y comparte a lo largo de la ejecución. En última instancia podríamos usar esta entidad para trabajar con la base de datos ejectando SQL sin necesidad de usar las capacidades como ORM en toda su extensión, con sus modelos etc..
Session: Es un nivel superior de abstración que se situa por encima del Engine. Permite realizar transacciones con la base de datos de una manera orientada a objetos. Se crearán y destruirán durante la ejección de la aplcación según sea necesario. Se encarga de hacer los commits rollbacks.
Respuesta en SO interesante a este respecto
Otros conceptos interesantes:
Dialect: Los dialectos son los responsables de ‘traducir’ la sintaxis SQL genérica generada por SQLAlcemy a la sintaxis específica de la base de datos correspondiente. Por ejemplo, gestionar los tipos de datos es uno de los puntos más importantes en este proceso. Tenemos los siguientes disponibles de base:
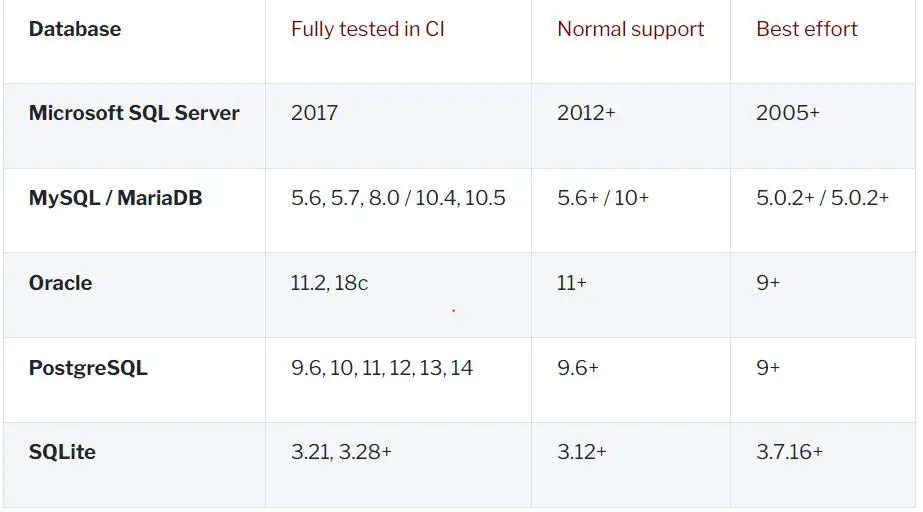
y estos son extensibles. Es decir, que si queremos algo extra como interacción con ElasticSearch u OpenSearch (AWS), debemos instalar(o implementar) sus dialectos específicos.
Como ejemplo, el módulo ElasticSearch dbapi.
Metadata: Se trata de un objeto que representa y contiene información sobre el esquema de base de datos. Por ejemplo las tablas, constraints, columnas, relaciones… Se usa internamente para generar las instrucciones SQL y para gestionar las migraciones.
Model: Un modelo en SQLALchemy es un objeto de Python que represena una tabla en base de datos. Heredan de DeclarativeBase.
Aquí tenemos un ejemplo sobre Postgres:
from sqlalchemy import Column, Integer, Float
from sqlalchemy.dialects.postgresql import UUID
from sqlalchemy.orm import DeclarativeBase
import uuid
class Base(DeclarativeBase):
pass
class Product(Base):
__tablename__ = "products"
id: uuid = Column(UUID(as_uuid=True), primary_key=True, default=uuid.uuid4)
price = Column(Float)
amount = Column(Integer)
def __repr__(self):
return f"""<Product(price='{self.price}', amount='{self.amount}', product_id='{self.product_id}')>"""¿Se pude tipar con mypy en SQLAlchemy v2.0?
Sí, a partir de esta versión no será necesario instalar stubs o módulos específicos para que el mapeo que realiza SQLAlchemy sea compatible con Mypy y con el reconocimiento de la sintaxis por los IDEs. Bastará con pip install sqlalchemy[mypy].
Siguientdo con el ejemplo anterior, el tipado estático quedaría:
from sqlalchemy import Column, Integer, Float
from sqlalchemy.dialects.postgresql import UUID
from sqlalchemy.orm import DeclarativeBase
import uuid
class Base(DeclarativeBase):
pass
class OrderNew(Base):
__tablename__ = "orders_new"
id: uuid = Column(UUID(as_uuid=True), primary_key=True, default=uuid.uuid4)
price: float = Column(Float)
amount: int = Column(Integer)
description: str | None = Column(Integer)
def __repr__(self):
return f"""<Order(price='{self.price}', amount='{self.amount}', product_id='{self.product_id}')>"""¿Cuándo usar sessionmaker()?
Nos permite crear una factoría de sesiones, configurando el comportamiento de las sesiones desde un solo lugar. Podemos con ello además separar la configuración de las sesiones de su creación, reduciendo duplicidades de código.
¿Qué son los Eventos ORM?
Mediante la API de eventos de SQLAlchemy, podemos configurar listeners que desencadenen la ejecución de determinadas funciones definidas por el usuario. Se usa o bien la función listen() o el decorador @listen_for(). Por ejemplo, esto puede ser útil en el caso de necesitar refrescar credenciales, loggear…
Aquí tenemos un ejemplo:
from sqlalchemy import create_engine
from sqlalchemy.event import listens_for
engine = create_engine('sqlite:///typethepipe.db')
@listens_for(engine, "do_connect", named=True)
def aws_token(cparams, **kw):
cparams['password'] = get_temp_token()
print("AWS token provisioned")Si quieres profundizar en los eventos de SQLA, os dejamos link a la docu como siguiente paso.
¡Sigue leyendo nuestros Python Posts!
Carlos Vecina
Senior Data Scientist at Jobandtalent
Senior Data Scientist at Jobandtalent | AI & Data Science para aportar valor en la empresa